
I recently obtained certification as a Big Data Scientist from Arcitura within the framework of the third call for transversal skills offered by the MinTIC of Colombia. Among the many topics that can be addressed with data science is the detection of atypical data or outliers, applicable for example in investigations of fraudulent banking transactions or to find faulty parts in a production chain.
There are different types of outliers:
- Global Outliers– Data that is inconsistent without any conditions, for example, a fraudulent bank transaction.
- Contextual Outliers: data that is only inconsistent within a specific context or condition, for example, a person of average weight constitutes an outlier within a sumo wrestling competition.
- Collective Outliers: data that is inconsistent only when combined with other similar data, without conditions or context, for example, several low-value bank deposits from several bank accounts may indicate money laundering when analyzed collectively.
The model for detecting outlier data can be based on the statistics or in algorithms machine learning.
Statistical Techniques
Statistical techniques work on the basis of fitting a distribution. Once the distribution is known, the values that fall within the low probability area of the distribution can be identified as outliers.
Parametric approach
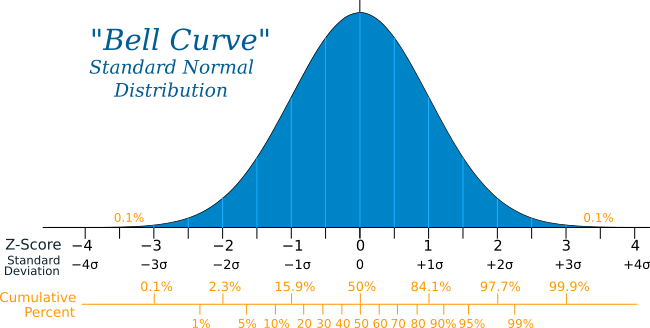
It is assumed that the data generating process produces data that fit a particular probability distribution such as normal distribution. With the corresponding probability density function, the probability of a value can be determined. This process requires the estimation of the parameters of the distribution as the mean and standard deviation.
A common test for univariate analysis of continuous data is the worth z which determines that for a normal distribution, any z value that is more than three standard deviations from the mean in any direction is considered an outlier.
Non-parametric approach
In this approach the probability distribution is not assumed. The data generating process is modeled solely based on the data produced.
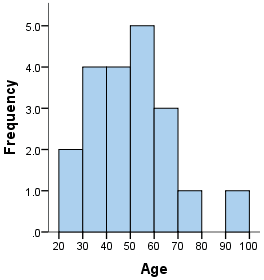
A common nonparametric technique for identifying outliers in discrete data is the histogram. If a data item does not belong to any of the intervals in the diagram, it is considered an outlier.
He interquartile range (IQR) It can also be considered as a non-parametric statistical technique for detecting outliers.
Machine Learning Algorithms
Distance-based techniques
These techniques are based on the assumption that in a multidimensional space, data points can be considered normal when they are close to each other. Outliers are those that are far from those normal points.
Supervised technique
It is based on a learning approach in which there are some known examples of outlier data that are provided to the algorithm to develop an outlier detection model.
It builds a single class classification model which only models normal examples, thus, any instance that does not belong to the normal class constitutes an outlier.
Semi-supervised technique
First used clustering to create natural clusters before applying the algorithm single class classification. With the single-class algorithm, instances that are not marked but that already belong to a cluster are labeled according to the instances that are already classified within those clusters.
Any instance or cluster that does not belong to any normal class is considered an outlier.
As has been seen, there are many techniques in data science for detecting outlier data. The technique to use in each case will depend on various factors such as the type of variable (discrete or continuous), the number of variables involved (univariate or multivariate analysis) and the nature of the data generating process.



