
Recientemente obtuve la certificación como Big Data Scientist por parte de Arcitura en el marco de la tercera convocatoria de competencias transversales ofrecida por el MinTIC de Colombia. Dentro de los muchos temas que se pueden abordar con la ciencia de datos está la detección de datos atípicos o outliers, aplicable por ejemplo en investigaciones de transacciones bancarias fraudulentas o para encontrar partes con fallas en una cadena de producción.
Existen diferentes tipos de outliers:
- Outliers globales: datos que son inconsistentes sin ninguna condición, por ejemplo, una transacción bancaria fraudulenta.
- Outliers contextuales: datos que sólo son inconsistentes dentro de un contexto o condición específica, por ejemplo, una persona con un peso promedio constituye un elemento atípico dentro de una competencia de lucha de sumo.
- Outliers colectivos: datos que son inconsistentes sólo cuando se combinan con otros datos similares, sin condiciones ni contexto, por ejemplo, varios depósitos bancarios de poco valor desde varias cuentas bancarias pueden indicar lavado de dinero al ser analizados colectivamente.
El modelo para la detección de datos atípicos puede estar basado en la estadística o en algoritmos de machine learning.
Técnicas Estadísticas
Las técnicas estadísticas funcionan sobre la base del ajuste de una distribución. Una vez se conoce la distribución, los valores que quedan dentro del área de baja probabilidad de la distribución pueden ser identificados como outliers.
Enfoque paramétrico
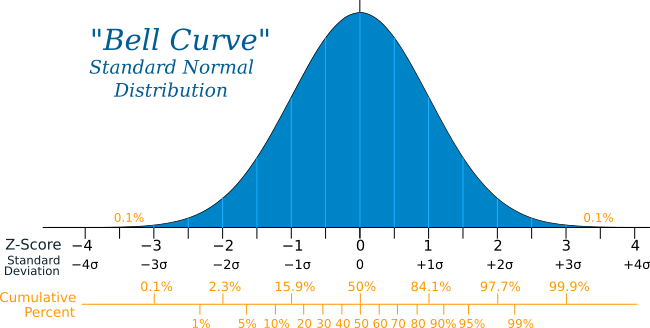
Se asume que el proceso generador de los datos produce datos que se ajustan a una distribución de probabilidad particular como la distribución normal. Con la función de densidad de probabilidad correspondiente, se puede determinar la probabilidad de un valor. Este proceso requiere la estimación de los parámetros de la distribución como la media y la desviación estańdar.
Un test común para el análisis univariado de datos continuos es el valor z el cual determina que para una distribución normal, cualquier valor z que esté a más de tres desviaciones estándar de la media en cualquier dirección es considerado un outlier.
Enfoque no paramétrico
En este enfoque no se asume la distribución de probabilidad. El proceso generador de los datos es modelado solamente con base en los datos producidos.
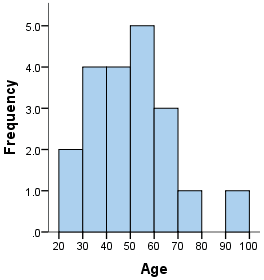
Una técnica no paramétrica común para identificar outliers en datos discretos es el histograma. Si un dato no pertenece a ninguno de los intervalos del diagrama, es considerado un outlier.
El rango intercuartil (IQR) también puede ser considerado como una técnica estadística no paramétrica para la detección de outliers.
Algoritmos de Machine Learning
Técnicas basadas en la distancia
Estas técnicas se basan en la suposición de que en un espacio de multidimensional, los puntos de datos pueden ser considerados normales cuando están cerca unos de otros. Los outliers son aquellos que están lejos de esos puntos normales.
Técnica supervisada
Está basada en un enfoque de aprendizaje en el que existen algunos ejemplos conocidos de datos atípicos que se proveen al algoritmo para desarrollar un modelo de detección de outliers.
Se construye un modelo de clasificación de una sola clase que sólo modela ejemplos normales, así, cualquier instancia que no pertenezca a la clase normal constituye un outlier.
Técnica semi-supervisada
Primero se usa clustering para crear clusters naturales antes de aplicar el algoritmo de clasificación de una sola clase. Con el algoritmo de una sola clase se etiquetan las instancias que no están marcadas pero que ya pertenecen a un cluster, según las instancias que ya están clasificadas dentro de esos clusters.
Toda instancia o cluster que no pertenezca a ninguna clase normal es considerado como outlier.
Como se ha visto, existen muchas técnicas en la ciencia de datos para la detección de datos atípicos. La técnica a utilizar en cada caso dependerá de diversos factores como el tipo de variable (discreta o continua), la cantidad de variables involucradas (análisis univariado o multivariado) y la naturaleza del proceso generador de los datos.



